雪花模式
雪花模式
雪花模式是一种多维模型中表的逻辑布局,其实体关系图有类似于雪花的形状,因此得名。与星型模式相同,雪花模式也是由事实表和维度表所组成。所谓的“雪花化”就是将星型模式中的维度表进行规范化处理。当所有的维度表完成规范化后,就形成了以事实表为中心的雪花型结构,即雪花模式。将维度表进行规范化的具体做法是,把低基数的属性从维度表中移除并形成单独的表。基数指的是一个字段中不同值的个数,如主键列具有唯一值,所以有最高的基数,而像性别这样的列基数就很低。
在雪花模式中,一个维度被规范化成多个关联的表,而在星型模式中,每个维度由一个单一的维度表所表示。一个规范化的维度对应一组具有层次关系的维度表,而事实表作为雪花模式里的子表,存在具有层次关系的多个父表。
星型模式和雪花模式都是建立维度数据仓库或数据集市的常用方式,适用于加快查询速度比高效维护数据的重要性更高的场景。这些模式中的表没有特别的规范化,一般都被设计成一个低于第三范式的级别。
数据规范化与存储
规范化的过程就是将维度表中重复的组分离成一个新表,以减少数据冗余的过程。正因为如此,规范化不可避免地增加了表的数量。在执行查询的时候,不得不连接更多的表。但是规范化减少了存储数据的空间需求,而且提高了数据更新的效率。这点在前面介绍关系模型时已经进行了详细的讨论。
从存储空间的角度看,典型的情况是维度表比事实表小很多。这就使得雪花化的维度表相对于星型模式来说,在存储空间上的优势没那么明显了。举例来说,假设在220个区县的200个商场,共有100万条销售记录。星型模式的设计会产生1,000,200条记录,其中事实表1,000,000条记录,商场维度表有200条记录,每个区县信息作为商场的一个属性,显式地出现在商场维度表中。在规范化的雪花模式中,会建立一个区县维度表,该表有220条记录,商场表引用区县表的主键,有200条记录,事实表没有变化,还是1,000,000条记录,总的记录数是1,000,420(1,000,000+200+220)。在这种特殊情况(作为子表的商场记录数少于作为父表的区县记录数)下,星型模式所需的空间反而比雪花模式要少。如果商场有10,000个,情况就不一样了,星型模式的记录数是1,010,000,雪花模式的记录数是1,010,220,从记录数上看,还是雪花模型多。但是,星型模式的商场表中会有10,000个冗余的区县属性信息,而在雪花模式中,商场表中只有10,000个区县的主键,而需要存储的区县属性信息只有220个,当区县的属性很多时,会大大减少数据存储占用的空间。
有些数据库开发者采取一种折中的方式,底层使用雪花模型,上层用表连接建立视图模拟星型模式。这种方法既通过对维度的规范化节省了存储空间,同时又对用户屏蔽了查询的复杂性。但是当外部的查询条件不需要连接整个维度表时,这种方法会带来性能损失。
优点
雪花模式是和星型模式类似的逻辑模型。实际上,星型模式是雪花模式的一个特例(维度没有多个层级)。某些条件下,雪花模式更具优势:
- 一些OLAP多维数据库建模工具专为雪花模型进行了优化。
- 规范化的维度属性节省存储空间。
缺点
雪花模型的主要缺点是维度属性规范化增加了查询的连接操作和复杂度。相对于平面化的单表维度,多表连接的查询性能会有所下降。但雪花模型的查询性能问题近年来随着数据浏览工具的不断优化而得到缓解。
和具有更高规范化级别的事务型模式相比,雪花模式并不确保数据完整性。向雪花模式的表中装载数据时,一定要有严格的控制和管理,避免数据的异常插入或更新。
示例
下图是将星型模式规范化后的雪花模式。日期维度分解成季度、月、周、日期四个表。产品维度分解成产品分类、产品两个表。由商场维度分解出一个地区表。
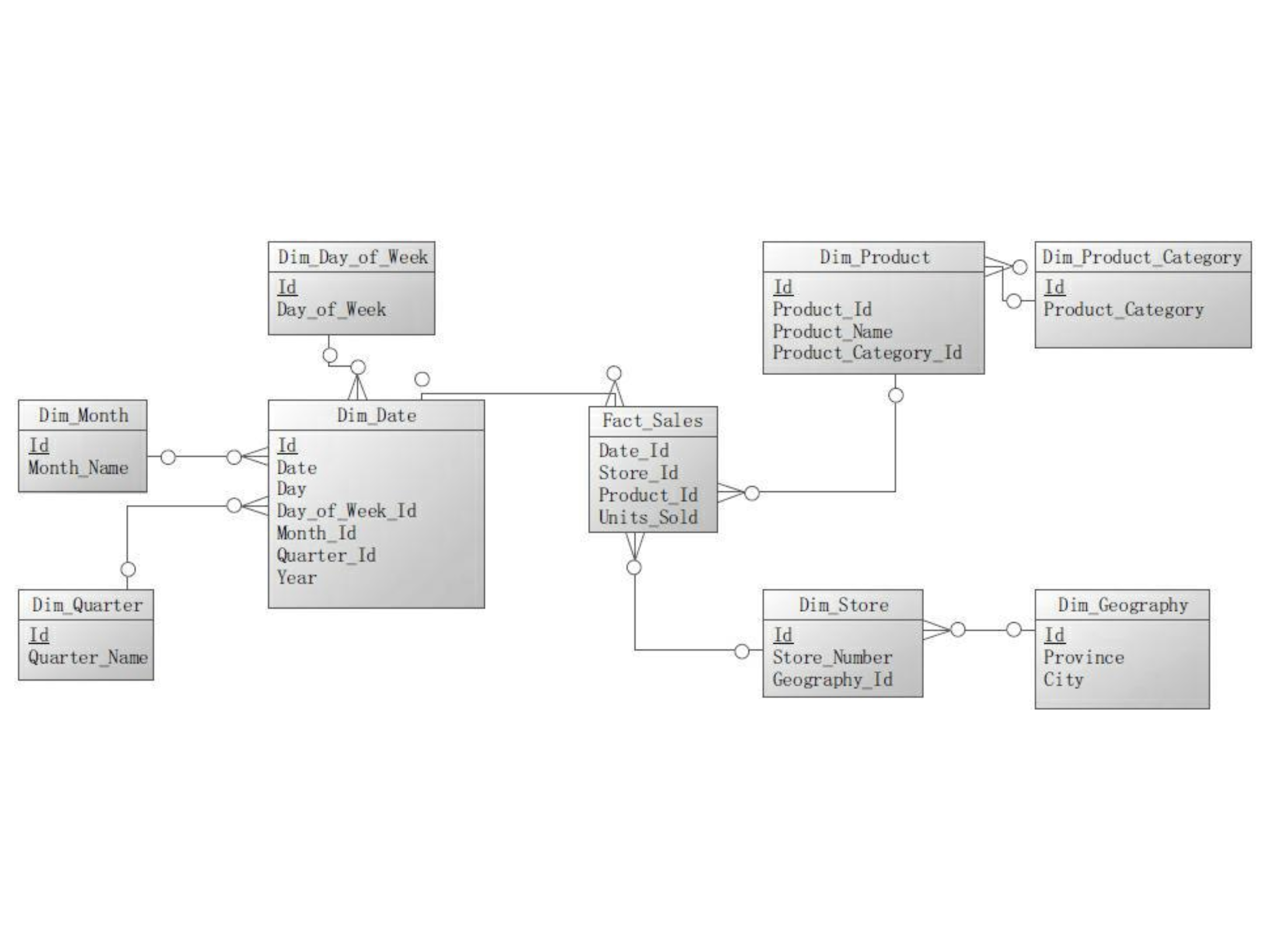
下面所示的查询语句的结果等价于前面星型模式的查询,可以明显看到此查询比星型模式的查询有更多的表连接。
select g.city,sum(f.units_sold)
from fact_sales f
inner join dim_date d on f.date_id = d.id
inner join dim_store s on f.store_id = s.id
inner join dim_geography g on s.geography_id = g.id
inner join dim_product p on f.product_id = p.id
inner join dim_product_category c on p.product_category_id = c.id
where d.year = 2015 and c.product_category = 'mobile'
group by g.city;