Hive的体系结构
Hive的体系结构
为了更好地理解Hive如何与Hadoop的基本组件一起协同工作,可以把Hadoop看作一个操作系统,HDFS和MapReduce是这个操作系统的组成部分,而像Hive、HBase这些组件,则是操作系统的上层应用或功能。Hadoop生态圈的通用底层架构是HDFS提供分布式存储,MapReduce为上层功能提供并行处理能力。

在HDFS和MapReduce之上,图中显示了Hive驱动程序和元数据存储。Hive驱动程序及其编译器负责编译、优化和执行HiveQL。依赖于具体情况,Hive驱动程序可能选择在本地执行Hive语句或命令,也可能是产生一个MapReduce作业。Hive驱动程序把元数据存储在数据库中。
默认配置下,Hive在内建的Derby关系数据库系统中存储元数据,这种方式被称为嵌入模式。在这种模式下,Hive驱动程序、元数据存储和Derby全部运行在同一个Java虚拟机中(JVM)。这种配置适合于学习目的,它只支持单一Hive会话,所以不能用于多用户的生产环境。Hive还允许将元数据存储于本地或远程的外部数据库中,这种设置可以更好地支持Hive的多会话生产环境。并且,可以配置任何与JDBC API兼容的关系数据库系统存储元数据,如MySQL、Oracle等。
对应用支持的关键组件是Hive Thrift服务,它允许一个富客户端访问Hive,开源的SQuirreL SQL客户端被作为示例包含其中。任何与JDBC兼容的应用,都可以通过绑定的JDBC驱动访问Hive。与ODBC兼容的客户端,如Linux下典型的unixODBC和isql应用程序,可以从远程Linux客户端访问Hive。如果在客户端安装了相应的ODBC驱动,甚至可以从微软的Excel访问Hive。通过Thrift还可以用Java以外的程序语言,如PHP或Python访问Hive。就像JDBC、ODBC一样,Thrift客户端通过Thrift服务器访问Hive。
架构图的最上面包括一个命令行接口(CLI),可以在Linux终端窗口向Hive驱动程序直接发出查询或管理命令。还有一个简单的Web界面,通过它可以从浏览器访问Hive管理表及其数据。
一、Hive 的工作流程
从接收到从命令行或是应用程序发出的查询命令,到把结果返回给用户,期间Hive的工作流程(第一版的MapReduce)如下图,从中不难看出,Hive的执行过程与关系数据库的非常相似,只不过是使用分布式计算框架来实现。
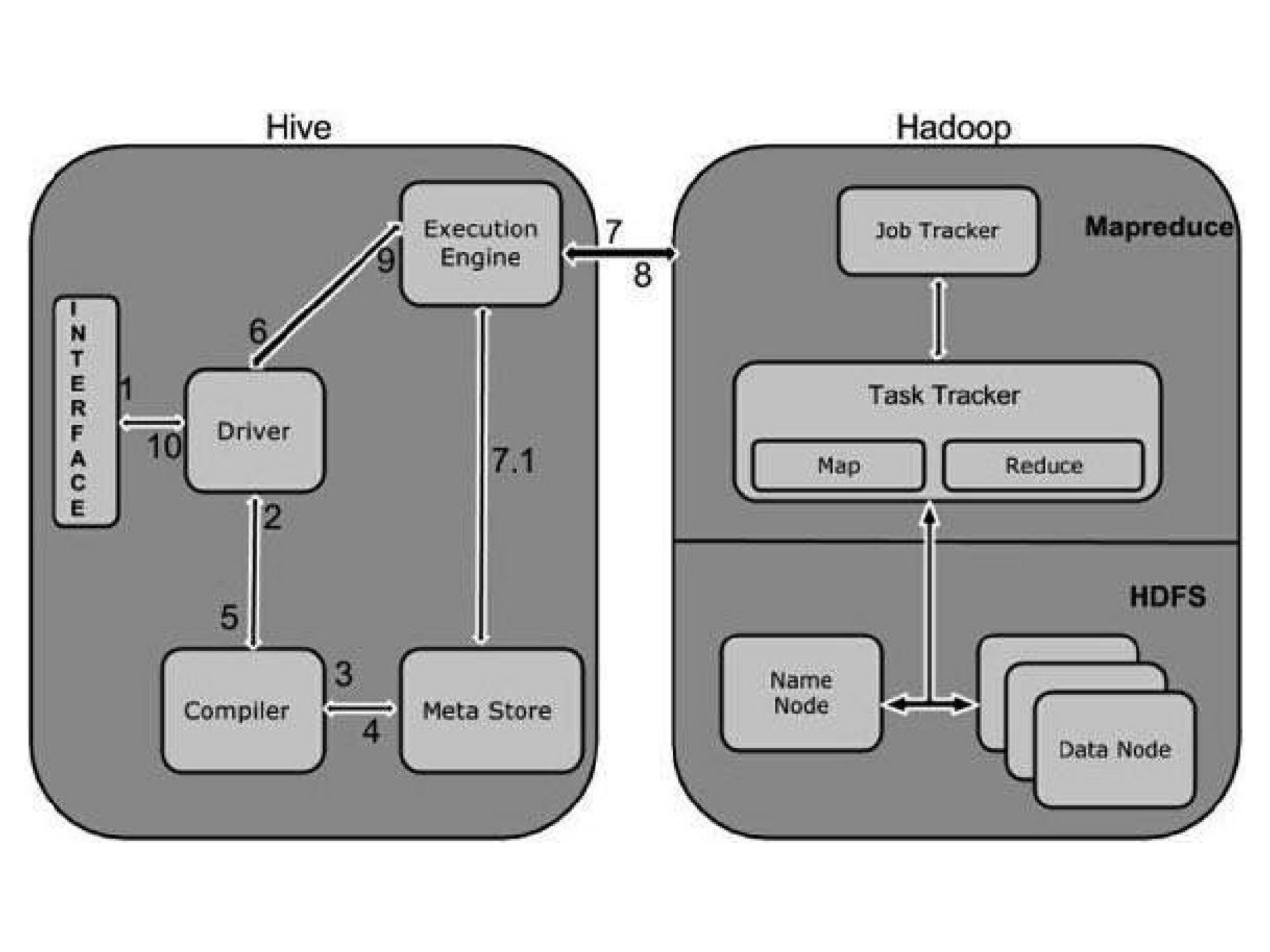
| 步骤 | 操作 |
|---|---|
| 1.执行查询 | 从Hive的CLI或Web UI发查询命令给驱动程序(任何JDBC、ODBC数据库驱动)执行 |
| 2.获得计划 | 驱动程序请求查询编译器解析查询、检查语法、生成查询计划或者查询所需要的资源 |
| 3.获得元数据 | 编译器向元数据存储数据库发送元数据请求 |
| 4.发送元数据 | 作为响应,元数据存储数据库向编译器发送元数据 |
| 5.发送计划 | 编译器检查需要的资源,并把查询计划发送给驱动程序。至此,查询解析完成 |
| 6.执行计划 | 驱动程序向执行引擎发送执行计划 |
| 7.执行作业 | 执行计划的处理是一个MapReduce作业。执行引擎向Name node上的JobTracker进程发送作业,JobTracker把作业分配给Data node上的TaskTracker进程,此时,查询执行MapReduce作业 |
| 7.1操作元数据 | 执行作业的同时,执行引擎可能会执行元数据操作,如DDL语句等。 |
| 8.取回结果 | 执行引擎从Data node 接收结果 |
| 9.发送结果 | 执行引擎向驱动程序发送合成的结果值 |
| 10.发送结果 | 驱动程序向Hive接口(CLI或者WebUI)发送结果 |
二、Hive客户端
Hive最初的形式是一个重量级的命令行工具,它接收查询指令并利用MapReduce执行查询。后来Hive采用了客户端-服务器模式,HiveServer(简称HS1)作为服务器端,负责将查询语句编译成MapReduce作业,并监控它们的执行。而Hive CLI(hive shell命令)是一个命令行接口,负责接收用户的HiveQL语句,并传送到服务器。 Hive社区在0.11版中引入了HS2,并推荐使用新的Beeline命令行接口(beeline shell命令),HS1及其Hive CLI不再建议使用,甚至过时的Hive CLI客户端方案以后可能将不能与HS2一起使用。下面重点介绍Beeline客户端,在本小节最后说明Hive CLI和Beeline用法上的主要差别。
Beeline是为与新的Hive服务器进行交互而特别开发的。与Hive CLI不同,Beeline不是基于Thrift的客户端,而是一个基于SQLLine CLI的JDBC客户端,尽管用于和HS2通信的JDBC驱动程序还是使用的Thrift API。Beeline有嵌入和远程两种操作模式。在嵌入模式中,它运行一个嵌入的类似于hive的shell命令;而在远程模式中,它通过Thrift服务连接一个分离的HS2进程。从Hive 0.14开始,当Beeline与HS2联合使用时,还会在交互式查询中打印很长的HS2消息信息。生产系统推荐使用远程HS2模式,因为它更安全,不需要授予用户直接访问HDFS或元数据存储的权限。
Beeline命令
$HIVE_HOME/bin/beeline这个shell命令(后面简称为beeline)用于连接Hive服务器。假定已经将$HIVE_HOME/bin加入到环境变量PATH中,则只需要在shell提示符中输入beeline,就可以使用户的shell环境如bash找到这个命令。\
# 进入Beeline后链接服务器
beeline > !connect jdbc:hive2://cdh2:10000也可以在命令行直接指定连接参数。这意味着能够在Linux shell的命令历史history中找到含有连接字符串的beeline命令。
beeline -u jdbc:hive2://cdh2:10000/test连接URL
Beeline客户端使用URL格式连接Hive数据库,HS2的URL连接字符串语法如下:
jdbc:hive2://<host1>:<port1>,<host2>:<port2>/dbName;initFile=<file>;sess_var_list?hive_conf_l ist#hive_var_list
<host1>:<port1>,<host2>:<port2>:要连接的一个服务器实例,或者是用逗号分隔的多个服务器实例,如果为空,将使用嵌入模式。- dbName:初始连接的数据库名称。
<file>:初始化脚本的路径(Hive 2.2.0及以后版本支持)。这个脚本文件中的HiveQL语句会在连接后自动执行。该选项可以为空。sess_var_list:以一个逗号分隔的、会话级变量的键/值对列表。hive_conf_list:以一个逗号分隔的、Hive配置变量的键/值对列表。hive_var_list:以一个逗号分隔的、Hive变量的键/值对列表。
JDBC连接具有jdbc:hive2://前缀,驱动的类是org.apache.hive.jdbc.HiveDriver。注意这和老的HS1不同。
对于远程连接模式,连接URL的格式为:
jdbc:hive2://<host>:<port>/<db>;initFile=<file>(HS2 默认的端口是 10000)。
对于嵌入连接模式,连接URL的格式为:
jdbc:hive2:///;initFile=<file>(没有主机名和端口)。
当HS2以HTTP模式运行时,连接URL的格式为:
jdbc:hive2://<host>:<port>/<db>;transportMode=http;httpPath=<http_endpoint>,其中 <http_endpoint>对应的是hive-site.xml文件中配置hive.server2.thrift.http.path 属性值,默认值为 cliservice。默认的HTTP传输端口为10001。
当HS2启用了SSL时,连接URL的格式为:
jdbc:hive2://<host>:<port>/<db>;ssl=true;sslTrustStore=<trust_store_path>;trustStorePassword= <trust_store_password>
其中<trust_store_path>是客户端信任文件所在路径,<trust_store_password>是访问信任文件所需的密码。相应HTTP模式的格式为:
jdbc:hive2://<host>:<port>/<db>;ssl=true;sslTrustStore=<trust_store_path>;trustStorePassword= <trust_store_password>;transportMode=http;httpPath=<http_endpoint>。
从Hive 2.1.0开始,Beeline支持命名URL连接串,这是通过环境变量实现的。如果使用!connect连接一个名称,而不是URL,那么Beeline会查找一个名为BEELINE_URL_<name>的环境变量。例如,如果命令为!connect blue,Beeline会查找BEELINE_URL_BLUE环境变量,并使用该变量的值做连接。对于系统管理员来说,为用户设置环境变量相对方便些,用户也不需要在每次连接时都键入完整的URL字符串。 !reconnect命令用于刷新已经建立的连接,如果已经执行!close命令关闭了连接,则不能再刷新连接。从Hive 2.1.0起,Beeline会记住一个会话最后成功连接的URL,这样即使已经运行了!close命令也能够重连。另外,如果用户执行了!save命令,连接会被保存到beeline.properties文件中,当执行!reconnect时,会连接到这个保存的URL。也可以在命令行使用-r参数,在启动Beeline时执行重连操作。
变量和属性
--hivevar参数可以让用户在命令行定义自己的变量以便在Hive脚本中引用,以满足不同情况的需要。这个功能只有Hive 0.8.0及其之后版本才支持。当使用这个功能时,Hive会将键/值对放到hivevar命名空间,这样就能和另外三种内置的命名空间(hiveconf、system和env)加以区分。下表描述了Hive的4种命名空间选项。
| 命名空间 | 使用权限 | 描述 |
|---|---|---|
| hivevar | 可读写 | 用户自定义变量(Hive 0.8.0及以后版本) |
| hiveconf | 可读写 | Hive相关的配置属性 |
| system | 可读写 | Java定义的配置属性 |
| Env | 只读 | shell环境(如bash)定义的环境变量 |
变量在Hive内部是以Java字符串的方式存储的。用户可以在查询中引用变量。Hive会先使用变量值替换掉查询的变量引用,然后才会将查询语句提交给查询处理器。在beeline环境中,可以使用set命令显示或者修改变量值。例如,下面这个会话先显示一个env变量的值,然后再显示所有命名空间中定义的变量。为了更清晰地表现,我们省略掉这个Hive会话中大量的输出信息:
set env:HOME;
set;
set -v;如果不加-v标记,set命令会打印出hivevar、hiveconf、system和env中所有的变量。使用-v标记,则会打印出Hadoop中所定义的所有属性。例如控制HDFS和MapReduce的属性。set命令还可用于给变量赋新的值。我们特别看下hivevar命名空间以及如何通过命令行定义一个变量:
beeline --hivevar foo=bar
0: jdbc:hive2://bihell:10000/default> set foo;
+----------+--+
| set |
+----------+--+
| foo=bar |
+----------+--+
1 row selected (6.41 seconds)
0: jdbc:hive2://bihell:10000/default> set hivevar:foo;
+-------------------+--+
| set |
+-------------------+--+
| hivevar:foo=bar2 |
+-------------------+--+
1 row selected (0.005 seconds)
0: jdbc:hive2://bihell:10000/default> set foo;
+-----------+--+
| set |
+-----------+--+
| foo=bar2 |
+-----------+--+
1 row selected (0.005 seconds)可以看到,前缀hivevar:是可选的,如果不加前缀,默认的命名空间就是hivevar。在beeline环境中,查询语句的变量引用会先被替换掉,然后才提交给查询处理器。
0: jdbc:hive2://bihell:10000/default> create table bihell(i int,${hivevar:foo} string);
+-----------+------------+----------+--+
| col_name | data_type | comment |
+-----------+------------+----------+--+
| i | int | |
| bar2 | string | |
+-----------+------------+----------+--+
0: jdbc:hive2://bihell:10000/default> create table bihell2 (i int,${foo} string);
+-----------+------------+----------+--+
| col_name | data_type | comment |
+-----------+------------+----------+--+
| i | int | |
| bar2 | string | |
+-----------+------------+----------+--+--hiveconf选项是hive 0.7版本后支持的功能,用于配置Hive行为的所有属性。我们甚至可以增加新的hiveconf属性。
0: jdbc:hive2://bihell:10000/default> set hiveconf:y=1;
No rows affected (0.002 seconds)
0: jdbc:hive2://bihell:10000/default> set hiveconf:y;
+---------------+--+
| set |
+---------------+--+
| hiveconf:y=1 |
+---------------+--+
1 row selected (0.005 seconds)
0: jdbc:hive2://bihell:10000/default> select * from t where id=${hiveconf:y);运行指定文件中的SQL
beeline -u "jdbc:hive2://xxx.xxx.com:10000" --hiveconf rptdate=`date --date='1 days ago' "+%Y%m%d"` -n hdfs -f /xx/xx/xx.SQL
# --hiveconf rptdate用来把变量带入SQL脚本,SQL脚本中使用${hiveconf:rptdate}获变量值。我们还有必要了解一下system命名空间,它定义Java系统属性。Beeline对这个命名空间内容具有可读写权利,而对于env命名空间的环境变量只提供读权限。
0: jdbc:hive2://bihell:10000/default> set ststem:user.name;
+--------------------------------+--+
| set |
+--------------------------------+--+
| ststem:user.name is undefined |
+--------------------------------+--+
1 row selected (0.005 seconds)
0: jdbc:hive2://bihell:10000/default> set system:user.name;
+------------------------+--+
| set |
+------------------------+--+
| system:user.name=hive |
+------------------------+--+
1 row selected (0.006 seconds)
0: jdbc:hive2://bihell:10000/default> set system:user.name=hive2;
No rows affected (0.007 seconds)
0: jdbc:hive2://bihell:10000/default> set system:user.name;
+-------------------------+--+
| set |
+-------------------------+--+
| system:user.name=hive2 |
+-------------------------+--+
1 row selected (0.005 seconds)
0: jdbc:hive2://bihell:10000/default> set env:HOME;
+-------------------------+--+
| set |
+-------------------------+--+
| env:HOME=/var/lib/hive |
+-------------------------+--+
1 row selected (0.005 seconds)
0: jdbc:hive2://bihell:10000/default> set env:HOME=/var/lib/hive2;
Error: Error while processing statement: null (state=,code=1)和hivevar变量不同,用户必须使用system:或者env:前缀来指定系统属性和环境变量。env命名空间可作为向Hive传递变量的一个可选的方式。
YEAR=2020
beeline -u jdbc:hive2://bihell:10000/test -e "select * from t where yar = ${env:YEAR}";查询处理器会在where子句中查看到实际的变量值为2020。Hive中所有的内置属性都在$HIVE_HOME/conf/hive-default.xml.template文件中列举出来了,这是个样例配置文件,其中还说明了这些属性的默认值。
输出格式
在Beeline中,查询结果能以不同的格式显示出来。显示格式可以通过outputformat选项设置。支持的输出格式有table、vertical、xmlattr、xmlelements和分隔值格式(csv、tsv、csv2、tsv2、dsv)。以下是一些不同格式的输出示例。
Hive CLI和Beeline使用上的主要差别
随着Hive从原始的HS1服务器进化为新的HS2,用户和开发者也需要将客户端工具从原来的Hive CLI切换为新的Beeline,然而这种切换并不只是将“hive”命令换成“beeline”命令这么简单。下面介绍两种客户端用法上的主要差异。
- Hive CLI提供了一个可以打印RCFile格式文件内容的工具,如:
hive --service rcfilecat /user/hive/warehouse/columntable/000000_0Beeline没有此项功能。 - Hive CLI可以使用source命令来执行脚本文件,如:
hive> source /path/to/file/queries.hql;Beeline没有此项功能。 - Hive CLI可以配置hive.cli.print.current.db属性,在命令行提示符前打印当前数据库名,如:
$hive -hiveconf hive.cli.print.current.db=true。Beeline使用--showDbInPrompt命令行参数实现此功能(2.2.0版本新增)。 - Hive CLI可以使用“!”操作符执行shell命令,如
hive> ! pwd;Beeline中不能执行shell命令,其中的“!”符号是用来执行Beeline命令的,如:beeline> !connect jdbc:hive2://cdh2:10000 - Hive CLI中,默认时在查询结果中不显示字段名称,需要设置hive.cli.print.header选项打印字段名称,如:
hive> set hive.cli.print.header=true;而Beeline不需要此项设置就会在输出中显示字段名称。 - Hive CLI中可以使用--define命令行参数设置变量,它和--hivevar是相同的,如:
hive --define foo=bar而在Beeline中--define参数是无效的,只能使用--hivevar参数。 - Hive CLI可以使用-S选项开启静默模式,这样可以在输出结果中去掉额外的输出信息,而Beeline虽然提供了-silent参数,似乎能起到相同的效果,但实际上不行(至少在CDH 5.7.0上,该参数和hive的-S作用是不同的)。
- Hive CLI支持管道符。例如,用户没有记清楚哪个属性指定了管理表的“warehouse”路径,通过如下的命令可以查看到:
hive -e "set" | grep warehouse上面的命令换成beeline则不会得到想要的结果。Beeline需要在客户端脚本中添加设置支持事务的set命令,即使在服务器端的hivesite.xml文件中已经设置,而Hive CLI则不需要。
三、数据类型
3.1 基本数据类型
Hive 表中的列支持以下基本数据类型:
| 大类 | 类型 |
|---|---|
| Integers(整型) | TINYINT—1 字节的有符号整数 SMALLINT—2 字节的有符号整数 INT—4 字节的有符号整数 BIGINT—8 字节的有符号整数 |
| Boolean(布尔型) | BOOLEAN—TRUE/FALSE |
| Floating point numbers(浮点型) | FLOAT— 单精度浮点型 DOUBLE—双精度浮点型 |
| Fixed point numbers(定点数) | DECIMAL—用户自定义精度定点数,比如 DECIMAL(7,2) |
| String types(字符串) | STRING—指定字符集的字符序列 VARCHAR—具有最大长度限制的字符序列 CHAR—固定长度的字符序列 |
| Date and time types(日期时间类型) | TIMESTAMP — 时间戳 TIMESTAMP WITH LOCAL TIME ZONE — 时间戳,纳秒精度 DATE—日期类型 |
| Binary types(二进制类型) | BINARY—字节序列 |
TIMESTAMP 和 TIMESTAMP WITH LOCAL TIME ZONE 的区别如下:
- TIMESTAMP WITH LOCAL TIME ZONE:用户提交时间给数据库时,会被转换成数据库所在的时区来保存。查询时则按照查询客户端的不同,转换为查询客户端所在时区的时间。
- TIMESTAMP :提交什么时间就保存什么时间,查询时也不做任何转换。
3.2 隐式转换
Hive 中基本数据类型遵循以下的层次结构,按照这个层次结构,子类型到祖先类型允许隐式转换。例如 INT 类型的数据允许隐式转换为 BIGINT 类型。额外注意的是:按照类型层次结构允许将 STRING 类型隐式转换为 DOUBLE 类型。

3.3 复杂类型
| 类型 | 描述 | 示例 |
|---|---|---|
| STRUCT | 类似于对象,是字段的集合,字段的类型可以不同,可以使用 名称.字段名 方式进行访问 | STRUCT ('xiaoming', 12 , '2018-12-12') |
| MAP | 键值对的集合,可以使用 名称[key] 的方式访问对应的值 | map('a', 1, 'b', 2) |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合,可以使用 名称[index] 访问对应的值 | ARRAY('a', 'b', 'c', 'd') |
3.4 示例
如下给出一个基本数据类型和复杂数据类型的使用示例:
CREATE TABLE students(
name STRING, -- 姓名
age INT, -- 年龄
subject ARRAY<STRING>, --学科
score MAP<STRING,FLOAT>, --各个学科考试成绩
address STRUCT<houseNumber:int, street:STRING, city:STRING, province:STRING> --家庭居住地址
) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";四、内容格式
当数据存储在文本文件中,必须按照一定格式区别行和列,如使用逗号作为分隔符的 CSV 文件 (Comma-Separated Values) 或者使用制表符作为分隔值的 TSV 文件 (Tab-Separated Values)。但此时也存在一个缺点,就是正常的文件内容中也可能出现逗号或者制表符。
所以 Hive 默认使用了几个平时很少出现的字符,这些字符一般不会作为内容出现在文件中。Hive 默认的行和列分隔符如下表所示。
| 分隔符 | 描述 |
|---|---|
| \n | 对于文本文件来说,每行是一条记录,所以可以使用换行符来分割记录 |
| ^A (Ctrl+A) | 分割字段 (列),在 CREATE TABLE 语句中也可以使用八进制编码 \001 来表示 |
| ^B | 用于分割 ARRAY 或者 STRUCT 中的元素,或者用于 MAP 中键值对之间的分割, 在 CREATE TABLE 语句中也可以使用八进制编码 \002 表示 |
| ^C | 用于 MAP 中键和值之间的分割,在 CREATE TABLE 语句中也可以使用八进制编码 \003 表示 |
使用示例如下:
CREATE TABLE page_view(viewTime INT, userid BIGINT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS SEQUENCEFILE;